
Acest articol vine ca o completare la primul articol (https://code-it.ro//introducere-in-retele-neuronale-teorie-si-aplicatii/) despre rețele neuronale, care tratează intuițiile din spatele acestora, cum au apărut și alte noțiuni introductive. În acest articol extind ce am început acolo la capitolul Modalități de învățare a rețelelor neuronale, într-o manieră mai sistematică.
Paradigmele învățării
Învăţarea automată, unul din subdomeniile de bază ale Inteligenţei Artificiale, se ocupă cu dezvoltarea de algoritmi şi metode ce permit unui sistem informatic să înveţe date, reguli, chiar algoritmi.Privite în ansamblu, mecanismele de învățare a rețelelor neuronale se pot împărți în două clase:
- Supravegheate – Fiindcă vorbim de un tip de învăţare inductivă ce pleacă de la un set de exemple numite instanţe de antrenare pe baza cărora se formează o ipoteză(model de evaluare, şablon) care permite clasificarea unor instanţe noi. Învăţarea este supravegheată în sensul că setul de exemple este dat împreună cu clasificarea lor corectă.
- Nesupravegheate – În acest caz setul de antrenare conține doar date de intrare. Un exmplu sunt algoritmii ce pot grupa datele pe categorii în funcție de similitudinea dintre ele.
- Se bazează pe proprietățile statistice ale datelor
- Nu se bazează pe conceptul de funcție de eroare ci pe cel de calitate a modelului extras din date, care trebuie maximizat prin procesul de antrenare.
Problema regresiei și a clasificării
Regresia și clasificarea fac parte din spectrul mai larg al problemelor de optimizare convexă [1]. Faptul că ambele probleme sunt de fapt aceeași fațetă a unui concept mai larg este un atuu, deoarece algoritmii construiți pentru o problemă pot fi rapid convertiți înspre a rezolva și problema complementară și vice-versa.
Diferența principală între o problemă de regresie și una de clasificare, este existența, în cazul celei din urmă, a unui criteriu de decizie. Criteriul de decizie este singurul factor care dă natura discriminatorie a clasificatorilor.
Ambele probleme pot fi rezolvate prin metoda celor mai mici pătrate, deoarece sunt probleme de optimizare fără constrângeri, unde obiectivul este minimizarea unei funcții de cost, ce semnifică apropierea de soluția globală.
În învățarea automată și în domeniul rețelelor neuronale se vorbește de funcția de cost sau de eroarea eșantionului. Printre cele mai cunoscute funcții de cost se numără costul pătratic:
\begin{aligned} \text{Regresie:} \quad E_{in}(w) &=\frac{1}{N}\sum_{i=1}^N(w^Tx_n-y_n) = \frac{1}{N}||\boldsymbol{Xw-y}||^2, \quad y_n \in \chi \\ \text{Clasificare:} \quad E_{in}(w)&=\frac{1}{N}\sum_{i=1}^N(g(w^Tx_n)-y_n) =\frac{1}{N}||\boldsymbol{g(Xw)-y}||^2, \quad y_n \in Bernoulli(\phi) \end{aligned}
\\
\text{unde} \qquad
\def\horzbar{\rule[.5ex]{2.5ex}{0.5pt}}
X =
\left[
\begin{array}{ccc}
\horzbar & x_1^T & \horzbar \\
\horzbar & x_2^T & \horzbar \\
& \vdots & \\
\horzbar & x_N^T & \horzbar
\end{array}
\right], \qquad
y =
\left[
\begin{array}{c}
y_1\\
y_2\\
\vdots\\
y_N
\end{array}
\right]În cazul regresiei liniare, soluția poate fi calculată direct și este suficient să găsim transformarea care va duce funcția convexă într-un minim global:
E_{in}(w)=\frac{1}{N}||\boldsymbol{Xw-y}||^2 \\ \nabla E_{in}(w)=\frac{2}{N}X^T(Xw-y)=0\\ X^TXw=X^Ty\\ w=X^{\dagger}y ~ \text{ unde } ~ X^{\dagger}=(X^TX)^{-1}X^T \\ X^{\dagger} \text{ este "pseudo-inversa"} \text{ lui X}Algoritmul de învățare a perceptronului
Perceptronul este neuronul cu funcția de activare treaptă, f(x;\theta)=sign(\theta^Tx) \equiv y\theta^Tx, cu acesta obținându-se primele rezultate semnificative în problemele de clasificare, dar și în teoria aproximatorilor booleni. \boldsymbol{\theta} \in \mathbb{R}^d reprezintă modelul ce trebuie estimat pe baza vectorilor de antrenare x_1,x_2,…,x_n și a etichetelor y_1,y_2,…,y_n.

Analiza de convergență a algoritmului
Pentru a demonstra convergența algoritmului de mai sus trebuie făcute două presupuneri:
- \|x_t\|\leqslant R, \forall t , unde R este o rază maximă în care se găsesc instanțe de antrenare
- Există un model, \theta^* > 0 , ce clasifică corect toate instanțele \Rightarrow \gamma > 0 astfel încât y_t(\theta^*)^T x_t \geqslant \gamma \quad \forall t=1,…,n . \gamma este o distanță dintre o etichetă și granița de decizie.
Pentru a demonstra convergența algoritmului este suficient:
- Să se arate că (\theta^*)^T\theta^{(k)} crește la fiecare actualizare
- Norma lui \theta^{(k)} crește cel mult liniar în numărul de actualizări k
\begin{aligned}(\theta^*)^T\theta^{(k)} &= (\theta^*)^T(\theta^{(k-1)}+y_kx_k) = (\theta^*)^T\theta^{(k-1)} + y_k(\theta^*)^Tx_k\\ (\theta^*)^T\theta^{(k)} &\geqslant (\theta^*)^T\theta^{(k-1)} + \gamma \geqslant … \geqslant k\gamma\\ \Vert\theta^{(k)}\Vert^2 &= \Vert\theta^{(k-1)}+y_tx_t\Vert^2 = \Vert\theta^{(k-1)}\Vert^2+2y_t(\theta^{(k-1)})^Tx_t+||x_t||^2\\ \Vert\theta^{(k)}\Vert^2 &\leqslant \Vert\theta^{(k-1)}\Vert^2 + \Vert x_t\Vert^2 \quad \text{deoarece actualizările se fac doar pe greșeli}. \\ & \leqslant \Vert\theta^{(k-1)}\Vert^2 + R^2 \leqslant … \leqslant kR^2\\ \cos(\theta^*, \theta^{(k)}) &= \frac{(\theta^*)^T\theta^{(k)}}{\Vert\theta^\Vert\Vert\theta^{(k)}\Vert} \geqslant \frac{k\gamma}{\Vert\theta^*\Vert\Vert\theta^{(k)}\Vert} \geqslant \frac{k\gamma}{\Vert\theta^*\Vert\sqrt{kR^2}} \ \Rightarrow \\ 1 &\geqslant \frac{k\gamma}{\Vert\theta^*\Vert\sqrt{kR^2}} \Rightarrow k \leqslant \frac{R^2\Vert\theta^*\Vert^2}{\gamma^2}\end{aligned}Ultimul rezultat este o constrângere ce arată că algoritmul perceptronului găsește un model consistent după un factor proporțional cu 1/\gamma^2 actualizări. Acest rezultat demonstrează că, în situațiile când problema poate fi complet separabilă în clase(fără eroare peste eșantionul datelor de antrenare) algoritmul este convergent. De asemenea, mărimea 1/\gamma^2 poate fi interpretată și ca o măsură a complexității problemei.
Metoda gradientului stohastic
Metoda a fost dezvoltată la sfârșitul anilor ’50 și, împreună cu variantele sale, este cea mai utilizată metodă pentru actualizarea ponderilor în rețelele neuronale.
Matematic, se presupune că ipoteză poate fi descrisă printr-un vector de ponderi \mathcal{H}={h_w} , cu h_w parametrizat de w\in\mathbb{R}^m și m\geqslant d . Funcția h_w este o funcție de forma sgn(f_w(x)) , unde f_w:\mathbb{R}^d\rightarrow\mathbb{R} este o funcție cu valori reale într-o clasă auxiliară \mathcal{F}. f_w este funcția care rezolvă partea dificilă a problemei, iar h_w convertește acea graniță de decizie într-o serie de clase.
În aplicarea gradientului stohastic, din setul instanțelor de antrenare, \chi, se extrage, aleator(de unde și natura stohastică a metodei), o instanță de antrenare cu ajutorul căreia se actualizează modelul, pe baza funcției de cost. Eroarea, E_{in}(f_w(x),f^*(x)), descrie o funcție cu valori reale, cu rol de penalizare, ce este asociată lui f_w pentru predicția ce a făcut-o asupra lui x atunci când valoarea lui adevărată era f^*.
Există două metode principale prin care se aplică efectiv gradientul stohastic:
- Învățare online: modelul se actualizează la fiecare apariție a unei noi instanțe de antrenare
- Învățare în mini-loturi: modelul se actualizează cu efectul cumulat al instanțelor de antrenare dintr-un lot cu dimensiune cunoscută.
\text{fie} \quad w=w_{init} \quad \text{și} \quad \lambda_1,\lambda_2,…\lambda_n - \text{rate de învățare}\\ (ex. \quad w_{init}=\vec{0} \quad \text{și} \quad \lambda_t=1 \quad \forall t=1,…,n \quad \text{sau} \quad 1/\sqrt{t})\\ \text{fie} \quad (x_1, f^*(x_1)),\ (x_2, f^*(x_2)),…,\ (x_n, f^*(x_n)) \\ \text{Având exemplul } (x_t, f^*(x_t)) \text{ calculăm } \nabla L(f_w(x_t), f^*(x_t)) \text{ în raport cu w}\\ \nabla L_w(f_w(x_t), f^*(x_t)) \in \mathbb{R}^m\ w \leftarrow w - \lambda_t\nabla L(f_w(t),f^*(x_t))Propagarea înapoi
Algoritmul propagării înapoi este poate cel mai important algoritm din spatele învățării rețelelor neuronale și motivul pentru care domeniul a cunoscut o creștere explozivă, după o perioadă relativ lungă de stagnare. Algoritmul rezolvă problema transmiterii erorii în interiorul rețelei, pornindu-se de la ultimul strat. Condiția principală pentru ca acest algoritm să funcționeze este derivabilitatea funcției de cost, respectiv de activare.
Intuiția din spatele acestui algoritm vine de la ideea că ponderile ar trebui să fie modificate în măsura în care acestea aduc o modificare, la final, ieșirii. Schimbarea unei ponderi modifică ieșirea unui neuron, aceasta putând fi, la rândul ei, intrare altor neuroni, de la nivelul straturilor viitoare. Odată ce schimbarea este propagată prin rețea până la ultimul strat, se poate calcula eroarea între iesirile rezultate și vectorul obiectiv. Acea eroare este propagată înapoi prin rețea, luându-se în calcul efectul cumulativ pe care neuronii din straturile viitoare îl au asupra fiecărui neuron din straturile anterioare.
Deși algoritmul pare să aibă o natură exponențială în numărul de neuroni, în realitate ea este de fapt pătratică. Motivul se datorează dependențelor care există numai între un strat, predecesorul și succesorul său.
Matematic, scopul propagării înapoi este calculul termenului \left(\frac{\partial E_{in}}{\partial w_{ij}}\right)^l , \boldsymbol l fiind indexul stratului în care ponderea \boldsymbol i a neuronului \boldsymbol j se află. Odată cunoscută această valoare se poate actualiza ponderea, cu regula prezentată în cazul gradientului stohastic.
Se pot distinge două situații:
- Când trebuie calculată variația erorii în raport cu o pondere a unui neuron aflat într-un strat de ieșire. în această situație putem calcula direct derivata costului și o putem propaga la ponderea neuronului de ieșire folosind regula produsului (Figura 1).
- Când trebuie calculată variația erorii în raport cu o pondere a unui neuron aflat într-un strat ascuns. În aceast caz trebuie acumulate erorile pe care ponderea respectivă o induce neuronilor legați la ieșirea neuronului de care aparține. Matematic, vorbim de un caz al diferențialei totale exacte (Figura 2).

O observație interesantă constă în utilizarea funcției de cost pentru o singură instanță, fără a mai lua în calcul și rolul celorlalte instanțe. În cazul învățării online, efectul final este asemenea, deoarece formula funcției de cost este de fapt expectanța aplicării costului pe toate instanțele de antrenare.
În cazul stratului de ieșire, având \boldsymbol{N} instanțe de antrenare:
\text{fie eroarea pătratică } \quad E_{in}=\frac{1}{2N}\sum_{i=1}^N(y_j-o_j)^2 \quad \text{și} \quad e=\frac{1}{2}(y_j-o_j)^2\\ \text{rețeaua are ca funcție de activare sigmoida: } \quad \varphi(x)=\frac{1}{1+e^{-x}} \\ \frac{\partial e}{w_{ij}} = \frac{\partial e}{\partial o_j}\frac{\partial o_j}{\partial \Sigma_j}\frac{\partial \Sigma_j}{w_{ij}} \\ \frac{\partial e}{\partial o_j}=\frac{1}{2}2(y_j-o_j)(-1)=(o_j-y_j) \\ \frac{\partial o_j}{\partial \Sigma_j}\equiv \frac{\partial \varphi(\Sigma_j)}{\partial \Sigma_j} = \varphi(\Sigma_j)(1-\varphi(\Sigma_j)) = o_j(1-o_j)\\ \frac{\partial \Sigma_j}{\partial w_{ij}}=\frac{\partial}{\partial w_{ij}} \sum_{k=1}^m(w_{kj}o_k)=o_i \quad \text{m - nr. de ponderi a neuronului j} \\ \text{Înlocuind în prima relație: } \Rightarrow \frac{\partial e}{w_{ij}}=(o_j-y_j)o_j(1-o_j)o_i \quad (1)În cazul unui strat ascuns, singura problemă este adusă de către termenul \frac{\partial e}{\partial o_j} deoarece aici nu mai există o metodă directă prin care să se poată compara ieșirea neuronului cu o valoare obiectiv. De aceea, acest termen trebuie calculat prin propagarea erorii de la straturile ulterioare. Fiind vorba de o diferențială totală exact, putem:
\text{fie L stratul curent, iar }L^+\text{ stratul următor.} \\ \text{Pentru un neuron } j \in L:\ \frac{\partial e}{\partial o_j} = \sum_{l\in L+}\frac{\partial e}{\partial o_l}\frac{\partial o_l}{\partial \Sigma_l}\frac{\partial \Sigma_l}{o_j}\\ \frac{\partial \Sigma_l}{o_j} = \frac{\partial}{\partial o_j} \sum_{k=1}^m(w_{kl}o_k)=w_{jl}Introducand în ecuația initială obținem formula generala a propagării înapoi pentru straturile ascunse:
\frac{\partial e}{w_{ij}}=o_j(1-o_j)o_i\sum_{l\in L+}\frac{\partial e}{\partial o_l}o_l(1-o_l)w_{jl} \quad (2)
Optimizări ai algoritmilor de învățare
Entropia încrucișată
În ecuațiile (1) și (2) s-a putut remarca o dependență în regula produsului de funcția de activare folosită la nivelul unui strat, în cazul de mai sus fiind vorba de sigmoidă, adică de produsul \varphi(\Sigma_j)(1-\varphi(\Sigma_j)) . În cazul sigmoidei, acest lucru nu este o problemă când valorile sumei sunt apropiate de 0 (valorile se împart în medie la 4, ceea ce corespunde unei învățări mai lente și mai precise). Problema pe care funcțiile de activare de natura sigmoidei o au este comportamentul lor atunci când sunt departe de 0. În aceste zone, derivata lor este foarte apropiată de 0, iar acest lucru implică o învățare foarte lentă a rețelei. O potențială soluție este găsirea unei funcții de cost a cărei formă să anuleze efectul derivatei funcției de activare.
Pentru funcția de cost pătratică, se cunoaște că \frac{\partial e}{\partial o_j} = (o_j-y_j). O funcție de cost cu derivata de forma \frac{o_j-y_j}{o_j(1-o_j)} ar anula efectul derivatei sigmoidei, regula de actualizare simplificându-se la: \frac{\partial e}{\partial w_{ij}} = (o_j-y_j)o_i.
\begin{aligned} \Rightarrow e(o_j)&=\int_{o_j} \frac{o_j-y_j}{o_j(1-o_j)}=\int_{o_j}(\frac{1}{1-o_j} - \frac{y_j}{o_j(1-o_j)})do_j\\ &=-log(1-o_j) - \int_{o_j} y(\frac{1}{a}+\frac{1}{1-a})do_j \\ e(o_j) &= - y_j\log o_j - (1-y_j)\log(1-o_j) \end{aligned}Metoda impulsului
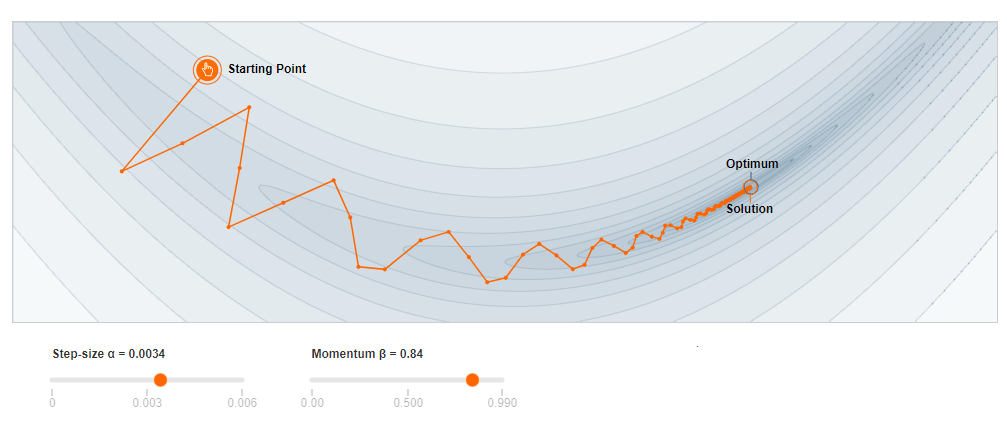
Metoda impulsului este o modificare subtilă adusă metodei gradientului. Cea din urmă, deși face îmbunătățiri monotonice la fiecare iterație, suferă de problema convergenței în minimele locale [2]. Această situație poate fi evitată mărind rata de învățare, dar acest lucru este riscant, din două motive:
- rata de învățare \alpha este prea mare, iar algoritmul, deși nu mai rămâne blocat în minime locale, nu poate ajunge la optimul global.
- Mai rău, în unele situații ajunge să ducă la un comportament divergent.
Modificarea propusă de metoda impulsului este introducerea unui nou termen, numit adesea \textit{viteză}, care să țină cont de starea anterioară.
v^{k+1}=\beta v^k + \nabla E_{in}(w^k) \ w^{k+1}=w^k-\alpha v^{k+1}Pentru valori mici ale hiperparametrului \beta metoda impulsului degenerează în metoda clasică a gradientului. Totuși, Nesterov [3], a demonstrat că, într-un cadru restrâns, această metodă este de fapt optimală.

Bibliografie
- S. Shalev-Shwartz and S. Ben-David, Understanding Machine Learning: From Theory to Algorithms. New York, NY, USA: Cambridge University Press, 2014.
- G. Goh, “Why momentum really works,” Distill, 2017. [Online]. Available: http://distill.pub/2017/momentum
- Y. Nesterov, Introductory Lectures on Convex Optimization: A Basic Course, 1st ed. Springer Publishing Company, Incorporated, 2014.